Insights
AI-Ready Data: The AI Gold Rush versus the Reality of Large Enterprise Data Infrastructure
July 24, 2025
Every company’s management demands AI. Boardrooms echo with terms like copilots and assistants. The reality? Million-dollar investments in data lakes that have become bottlenecks in the Generative AI era. Projects are stuck in pilot purgatory. Why?
The harsh truth is that research shows the primary cause of failed AI implementations can be traced not to model limitations or lack of computational power, but to inadequate data readiness in underlying datasets. Existing data architecture simply wasn’t designed for artificial intelligence needs. This fundamental misalignment is the biggest brake on real transformation.
Gartner’s prediction is unforgiving: by 2026, more than 60% of AI projects in organizations that don’t implement AI-ready data practices will fail and be abandoned. To overcome this barrier, it’s essential to understand the root of the problem—why traditional approaches fail.
The Problem: Traditional Data Infrastructure Failure in the AI Era
The strategic importance of understanding why modern data platforms, designed for Business Intelligence (BI), fail to support AI cannot be underestimated. The core problem doesn’t lie in the technology itself, but in its historical purpose. These systems were optimized for human users and historical reporting, which is fundamentally different from how modern AI agents work with data.
The Illusion of Readiness
The illusion of readiness is the false belief that owning modern data lakes, warehouses, and catalogs automatically means AI readiness. Companies should be “ready on paper” because they’ve invested enormous resources in their data infrastructure. In practice, however, these platforms become bottlenecks. When a new AI use case request arrives, creating the right data view still takes months. This leads to frustration among AI teams who can’t innovate, and impatience from business stakeholders who don’t see the promised return on investment.
Six Critical Gaps: Why BI-Built Platforms Fail
Traditional data architecture fails due to six critical gaps that reveal its fundamental incompatibility with AI requirements:
Data preparation limitations
Traditional data warehouses are optimized for historical reporting, not for real-time data consumption by artificial intelligence. AI requires dynamic, specialized, and rapidly accessible datasets, which conflicts with architecture designed for static, aggregated reports.
Limited unstructured data support
Thirty years of focus on structured data has left the most valuable enterprise knowledge—contained in documents, contracts, emails, and messages—trapped and inaccessible to AI.
Governance gaps
Compliance requirements for AI are fundamentally different from those for BI. While BI focuses on data integrity for reports, AI requires explainability, data lineage, and auditability as absolutely essential requirements for ensuring trustworthy autonomous decisions and regulatory compliance.
Missing evaluation frameworks
Traditional platforms lack systematic ways to test AI accuracy and reliability against specific business requirements. This gap prevents pilot projects from meeting business SLAs and is the main reason Gartner predicts the failure of more than 60% of projects.
Context overload problem
AI accuracy dramatically decreases when querying massive, unfiltered data lakes. The problem arises from excessive irrelevance, where AI agents are overwhelmed by enormous amounts of data, and from the fact that AI cannot understand context without semantic enrichment. This leads to unreliable results.
Inflexible data views
As mentioned, creating specialized datasets for specific AI use cases takes months, not days. This slowness prevents agile development and deployment of AI solutions.
To overcome these fundamental gaps, three new architectural pillars must be adopted to move data strategy into the artificial intelligence era.
Three Solution Pillars: Architectural Shift to AI Ready Data
Solving the above problems doesn’t lie in revolution and replacement of existing systems. It’s about their evolution—expanding with new layers designed specifically for AI needs. We present three key architectural pillars that will enable transforming existing data infrastructure into a high-performance engine for artificial intelligence.
Pillar 1: “AI Ready Data” Paradigm (for structured data)
The basic principle of the AI Ready Data paradigm is simple but transformational: Instead of querying huge data lakes hoping for accuracy, isolated, smaller datasets optimized for specific AI use cases must be prepared. This approach solves the context overload problem and inflexible data views.
Key requirements for achieving AI-ready state include:
- Use case-specific data preparation: Data must be prepared with specific AI needs in mind and must contain built-in evaluation datasets that enable continuous measurement of model performance and accuracy.
- Specialized APIs and views: Interfaces must be created that provide AI agents with only clean, relevant, and auditable data. This prevents overwhelming them with irrelevant information and protects core systems.
- Governance Frameworks: These frameworks must be designed for AI and include test datasets, verified test answers, and regulatory requirement coverage to ensure explainability and compliance.
- Continuous data qualification: Data must be continuously verified to maintain relevance and quality in line with constantly evolving business needs. This ensures persistent AI-ready state.
Pillar 2: Model Context Protocol (MCP) (for legacy systems)
Many companies face “The Legacy Anchor,” where critical data is trapped in systems like COBOL and mainframes. Integrating AI with these systems is extremely expensive and complex. For example, these systems’ APIs aren’t designed for AI-style queries—they can answer a query for one stock price but fail with queries like “show me all companies whose stocks rose by more than 10% yesterday.”
The solution is Model Context Protocol (MCP) – an abstraction layer functioning as an “AI-Ready API.” Think of it as a waiter: the AI agent (guest) doesn’t rush into the kitchen (legacy system) but tells the waiter (MCP) their request. The waiter knows how to translate this request into language the kitchen understands and brings exactly what was ordered.
MCP implementation varies based on the legacy system’s incompatibility level:
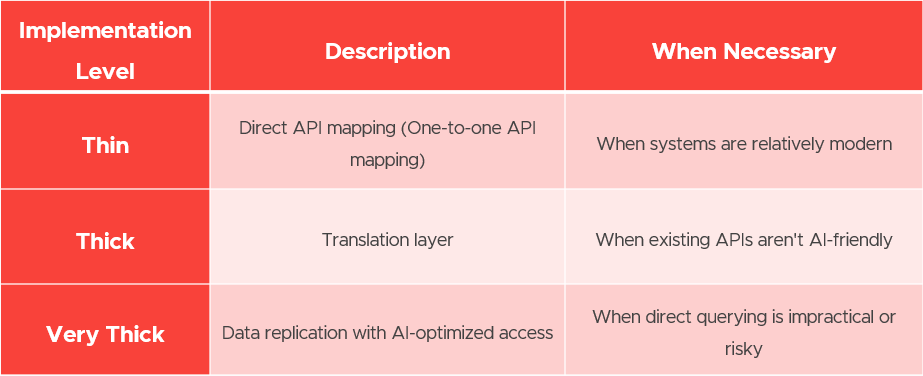
Pillar 3: Knowledge Representation (for unstructured data)
The most valuable corporate knowledge often doesn’t hide in tables but in documents, emails, and messages. This problem, called “The Unstructured Tsunami,” leads to a “Knowledge Crisis” rooted in 30 years of companies focusing 90% on structured data. Traditional approaches like simple chunk-and-embed in RAG systems often fail, lead to hallucinations, and loss of trust. The reason is that AI, unlike humans, cannot understand context without semantic enrichment.
The solution is Knowledge Representation – a new, essential knowledge layer above the data layer. For the first time in history, we need a knowledge layer above the data layer for AI to be truly successful.
Key components of this solution are:
- Semantic Enrichment: Raw text is enriched with context and meaning. For example, instead of storing bare patent text, the system adds information: “This patent uses genetic modification method X from the USA region.”
- Knowledge Graphs: These graphs structure relationships between entities (e.g., Method X → related patents → regional variations), enabling AI to perform precise, contextual queries.
- Hybrid Retrieval: The combination of metadata-based filtering, vector search, and reasoning layer overcomes traditional RAG limitations and provides accurate, reliable, and auditable answers.
These three pillars aren’t separate concepts. Their real power emerges when they combine into a unified architectural solution.
Solution and Vision: Knowledge Lake Architecture
The real power for Generative AI doesn’t arise from individual pillars in isolation, but from their intelligent integration. The Knowledge Lake vision represents the next evolutionary step in enterprise data architecture, integrating all three pillars into a cohesive whole.
Common Layer: Semantic Enrichment as the Key to Success
The intersection between the AI Ready Data paradigm and Knowledge Representation is the Semantic Enrichment Layer. This is where “clean, governed data meets meaning.” This layer is the true enabler of Generative AI. By connecting verified data with context, it enables AI assistants to become trustworthy, explainable, and compliant.
Knowledge Lake Architecture Components
The Knowledge Lake doesn’t replace existing data lakes but represents their evolution. A fundamental shift occurs: from providing raw data for analytical tools to providing structured knowledge for AI systems.
The Knowledge Lake architecture consists of the following main components:
- Phased structured and unstructured data from existing data lakes
- MCP access layers (thin/thick) for secure integration with legacy systems
- Knowledge graphs with semantic enrichment as the central element for storing context and relationships
- Metadata annotations connecting all layers and ensuring consistency
- Specialized storage for governance and evaluation-relevant data (test sets, versioned prompts, verified answers)
- Persistent storage for AI agent memory and audit trails of their decision-making
Proof from Practice: Case Studies
Transitioning to AI-ready data architecture isn’t just a technical exercise. It’s a strategic step that brings concrete, measurable, and sustainable business value across the entire organization.
Case Study: Global Bank (structured data challenge)
- Problem: A global bank faced a situation where legacy systems (COBOL, mainframes) and inflexible data warehouses caused integrating each new AI use case to take months. This extreme overhead and slowness prevented any innovation.
- Solution: A dedicated data platform was implemented that effectively decoupled AI initiatives from core systems. Specialized APIs (practical MCP implementation) were created that provided AI models with only clean, relevant, and auditable data. The solution included implementing a robust governance framework with test sets to ensure regulatory compliance.
- Result: The key business impact was dramatic acceleration of AI project delivery from months to weeks. This enabled deployment of several key AI solutions (e.g., risk scoring, transaction summarization) into production, which wasn’t previously possible.
Case Study: Investment Company (unstructured data challenge)
- Problem: Investment company analysts struggled to process massive, complex financial reports. Traditional RAG methods (chunk-and-embed) completely failed, generated unreliable answers, and led to deep frustration and loss of trust in AI.
- Solution: Hybrid search was implemented that combined vector search with full-document reasoning. The Knowledge Representation layer played a key role, providing data with necessary semantic context and accuracy. The MCP protocol was additionally used to overcome weak third-party APIs from which data was sourced.
- Result: There was a transformation from frustration to trust. AI-generated responses became reliable, complete, and fully auditable, significantly improving analysts’ work efficiency and output quality.
Business Benefits and Results
Transitioning to AI-ready data architecture isn’t just a technical exercise. It’s a strategic step that brings concrete, measurable, and sustainable business value across the entire organization.
Five Key Business Outcomes
- Return on Investment in Existing Infrastructure (ROI): This approach finally enables monetizing million-dollar investments in data warehouses and lakes beyond traditional reporting. Existing data sources become the foundation for high-value AI applications.
- Speed to Market: Deploying new AI use cases accelerates from months to weeks. Enterprises can respond faster to market opportunities and innovate ahead of competition.
- Risk Mitigation: By implementing proper governance, robust testing and evaluation frameworks, reliability, security, and predictability of AI systems are ensured, which is critical for their deployment in critical business processes.
- Competitive Advantage: Unlocking value from previously unused unstructured data provides access to knowledge that competitors don’t have. This information asymmetry becomes a source of sustainable competitive advantage.
- Regulatory Compliance: Architecture with built-in explainability and data lineage ensures full auditability and compliance with strict regulations like the EU AI Act.
Strategic Shift in Thinking
This approach requires a strategic shift in how we think about data and AI. Key principles are:
- Don’t replace, but extend and evolve the existing data ecosystem
- Don’t rebuild, but create AI-ready layers over existing systems
- Don’t wait, but start building these capabilities incrementally and focus on quick wins
This way, your existing data infrastructure finally transforms into the AI engine it was always meant to be.
Call to Action: Your First Quarter Plan
Success with AI isn’t about models themselves, but about systematically building data foundations. The following steps represent a practical and actionable plan to escape “pilot purgatory” and start building scalable AI solutions.
Week 1: Conduct an Uncompromising Audit
Audit your existing data architecture against the three pillars (AI Ready Data, MCP, Knowledge Representation) and identify the biggest weaknesses.
The audit should answer the following questions:
- Which AI use cases are stuck due to data preparation bottlenecks?
- What critical data is trapped in legacy systems and preventing innovation?
- Where are you losing trust in AI because it lacks proper context from unstructured data?
Month 1: Identify Highest-Value Quick Wins
Based on the audit, identify the most valuable opportunities that will bring rapid and visible impact. Focus on the following:
- Which legacy system integration using MCP can unlock the most AI use cases?
- Which unstructured data source contains the most valuable business knowledge that can be unlocked through Knowledge Representation?
- Which existing AI pilot could go into production if it had the right data foundations?
Quarter 1: Build Your First AI-Ready Capability
Transform identified opportunities into concrete results. Set a goal to build the first functional component of your new architecture:
- Implement an MCP server for the most critical legacy system
- Create a Knowledge Representation layer for the most valuable unstructured data
- Introduce first evaluation datasets for continuous measurement of AI quality and reliability
Conclusion: The Future Belongs to AI-Native Data Environments
The main idea is clear: Stop forcing traditional data architecture to serve AI. Start building data environments that are native to AI, that maintain persistent AI-ready states while scaling enterprise initiatives.
Companies that understand this first won’t just have better AI—they’ll have AI that actually works at enterprise scale and delivers real value.
The question is: will it be you?



