Insights
AI-Ready Data: Der KI-Goldrausch versus die Realität der Dateninfrastruktur in Großunternehmen
24. Juli 2025
Jede Unternehmensführung fordert KI. In den Boardrooms schwirren Begriffe wie Copiloten und Assistenten herum. Die Realität? Millionenschwere Investitionen in Data Lakes, die im Zeitalter der Generativen KI zu Engpässen geworden sind. Projekte stecken in der Pilot-Hölle fest. Warum?
Die harte Wahrheit ist, dass Studien zeigen: Die Hauptursache gescheiterter KI-Implementierungen liegt nicht an Modellbeschränkungen oder mangelnder Rechenleistung, sondern an unzureichender Datenbereitschaft (Data Readiness) in den zugrundeliegenden Datensätzen. Die bestehende Datenarchitektur wurde schlichtweg nicht für die Bedürfnisse künstlicher Intelligenz konzipiert. Diese fundamentale Diskrepanz ist die größte Bremse für echte Transformation.
Gartners Prognose ist unerbittlich: Bis 2026 werden mehr als 60% der KI-Projekte in Organisationen scheitern und aufgegeben werden, wenn keine AI-Ready bzw. KI-fähigen Datenpraktiken eingeführt werden. Um diese Barriere zu überwinden, muss die Ursache des Problems verstanden werden – warum traditionelle Ansätze versagen.
Das Problem: Versagen traditioneller Dateninfrastruktur im KI-Zeitalter
Die strategische Bedeutung des Verständnisses, warum moderne Datenplattformen, die für Business Intelligence (BI) entwickelt wurden, bei der KI-Unterstützung versagen, ist kaum zu überschätzen. Das Kernproblem liegt nicht in der Technologie selbst, sondern in ihrem historischen Zweck. Diese Systeme wurden für menschliche Benutzer und historisches Reporting optimiert, was grundlegend anders ist als die Art, wie moderne KI-Agenten mit Daten arbeiten.
Die Illusion der Bereitschaft
Die Illusion der Bereitschaft ist der falsche Glaube, dass der Besitz moderner Data Lakes, Data Warehouses und Kataloge automatisch KI-Bereitschaft bedeutet. Unternehmen sollten “auf dem Papier” bereit sein, weil sie enorme Ressourcen in ihre Dateninfrastruktur investiert haben. In der Praxis werden diese Plattformen jedoch zu Engpässen. Wenn eine neue AI-Use-Case-Anfrage kommt, dauert die Erstellung der richtigen Datensicht immer noch Monate. Das führt zu Frustration bei KI-Teams, die nicht innovieren können, und zur Ungeduld der Geschäftsseite, die den versprochenen ROI nicht sieht.
Sechs kritische Lücken: klassische BI-Architekturen im KI-Zeitalter versagen
Traditionelle Datenarchitekturen weisen sechs zentrale Lücken auf, die ihre grundlegende Inkompatibilität mit den Anforderungen moderner KI-Anwendungen offenlegen:
- Datenvorbereitung-Beschränkungen: Traditionelle Data Warehouses sind für historisches Reporting optimiert, nicht für den Echtzeit-Datenkonsum durch künstliche Intelligenz. KI benötigt dynamische, spezialisierte und schnell verfügbare Datensätze, was im Widerspruch zur Architektur steht, die für statische, aggregierte Reports entwickelt wurde.
- Eingeschränkte Unterstützung unstrukturierter Daten: Dreißig Jahre Fokus auf strukturierte Daten haben dazu geführt, dass das wertvollste Unternehmenswissen – enthalten in Dokumenten, Verträgen, E-Mails und Nachrichten – gefangen und für KI unzugänglich bleibt.
- Governance-Lücken: Compliance-Anforderungen für KI unterscheiden sich grundlegend von denen für BI. Während sich BI auf Datenintegrität für Reports konzentriert, sind für die KI Erklärbarkeit (Explainability), Data Lineage und Auditierbarkeit absolut unverzichtbare Anforderungen zur Gewährleistung vertrauenswürdiger autonomer Entscheidungen und regulatorischer Compliance.
- Fehlende Evaluationsframeworks: Traditionelle Plattformen haben keine systematischen Wege,KAI-Genauigkeit und -Zuverlässigkeit gegen spezifische Geschäftsanforderungen zu testen. Genau diese Lücke verhindert, dass Pilotprojekte geschäftliche SLAs erfüllen und ist der Hauptgrund, warum Gartner das Scheitern von mehr als 60% der Projekte prognostiziert.
- Kontext-Überlastungs-Problem: Die Genauigkeit von KI-Systemen sinkt drastisch, wenn sie auf ungefilterte, massive Data Lakes zugreifen müssen. Das Problem entsteht durch übermäßige Irrelevanz, wenn KI-Agenten von enormen Datenmengen überwältigt werden, und durch die Tatsache, dass KI ohne semantische Anreicherung keinen Kontext verstehen kann. Das führt zu unzuverlässigen Ergebnissen.
- Unflexible Datensichten: Wie erwähnt, dauert die Erstellung spezialisierter Datensätze für spezifische AI-Use-Cases Monate, nicht Tage. Diese Langsamkeit verhindert agile Entwicklung und Deployment von KI-Lösungen.
Um diese fundamentalen Lücken zu schließen, müssen drei neue architektonische Säulen übernommen werden, die die Datenstrategie ins Zeitalter der künstlichen Intelligenz führen.
Drei Lösungssäulen: Architektonischer Wandel zu AI-Ready Data
Die Lösung der beschriebenen Probleme liegt nicht in einer vollständigen Ablösung oder Revolution der bestehenden Systeme, sondern in ihrer gezielten Evolution. Unternehmen müssen ihre Datenarchitektur um neue Schichten erweitern, die speziell für die Anforderungen moderner KI-Anwendungen entwickelt wurden. Die folgenden drei architektonischen Säulen bilden das Fundament, um bestehende Datenlandschaften in eine leistungsfähige AI-Engine zu transformieren.
Säule 1: “AI-Ready Data” Paradigma (für strukturierte Daten)
Das Grundprinzip des AI-Ready Data Paradigmas ist einfach, aber hochwirksam: Statt riesige Data Lakes in der Hoffnung auf Genauigkeit abzufragen, müssen isolierte, kleinere Datensätze vorbereitet werden, die für spezifische AI-Use-Cases optimiert sind. Dieser Ansatz löst das Kontext-Überlastungs-Problem und unflexible Datensichten.
Schlüsselanforderungen für das Erreichen des AI-Ready Zustands umfassen:
- Use-Case-spezifische Datenvorbereitung: Daten müssen gezielt für den jeweiligen AI-Use-Case vorbereitet werden. Dazu gehören integrierte Evaluationsdatensätze, die eine kontinuierliche Messung von Modellgenauigkeit, Relevanz und Performance ermöglichen.
- Spezialisierte APIs und Views: Schnittstellen müssen erstellt werden, die KI-Agenten ausschließlich saubere, relevante und auditierbare Daten zur Verfügung stellen. Das verhindert ihre Überwältigung mit irrelevanten Informationen und schützt Core-Systeme.
- Governance Frameworks: Diese Frameworks müssen für KI entwickelt werden und Testdatensätze, verifizierte Testantworten und regulatorische Anforderungsabdeckung umfassen, um Erklärbarkeit und Compliance sicherzustellen.
- Kontinuierliche Datenqualifikation: Daten müssen kontinuierlich verifiziert werden, um Relevanz und Qualität im Einklang mit sich ständig entwickelnden Geschäftsbedürfnissen zu erhalten. Das gewährleistet persistente KI-Bereitschaft.
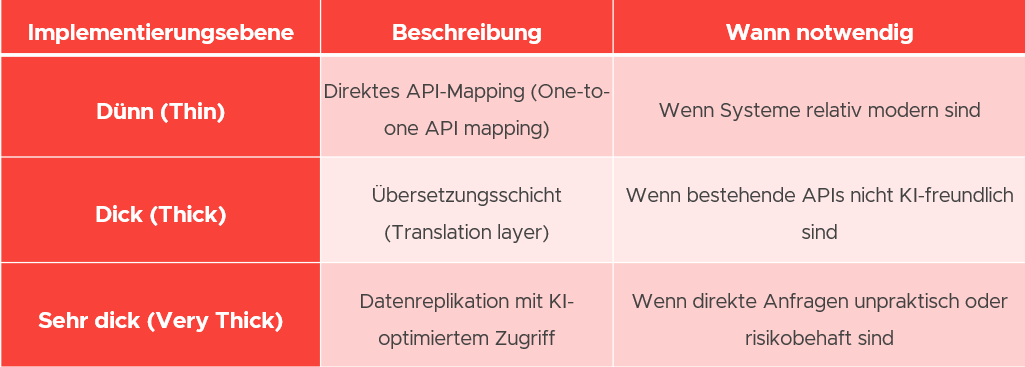
Säule 2: Model Context Protocol (MCP) (für Legacy-Systeme)
Viele Unternehmen kämpfen mit demLegacy Anchor”, wo kritische Daten in Systemen wie COBOL und Mainframes gefangen sind. Die Integration von KI mit diesen Systemen ist extrem teuer und komplex. Zum Beispiel sind diese System-APIs nicht für AI-Style-Queries entwickelt – sie können eine Abfrage nach einem Aktienkurs beantworten, versagen aber bei Queries wie “zeige mir alle Unternehmen, deren Aktien gestern um mehr als 10% gestiegen sind.”
Die Lösung ist Model Context Protocol (MCP) – eine Abstraktionsschicht, die als “AI-Ready API” funktioniert. Stellen Sie es sich als Kellner vor: Der KI-Agent (Gast) stürmt nicht in die Küche (Legacy-System), sondern teilt dem Kellner (MCP) seine Anfrage mit. Der Kellner weiß, wie er diese Anfrage in die Sprache übersetzen kann, die die Küche versteht, und bringt genau das, was bestellt wurde.
Die MCP-Implementierung variiert basierend auf dem Inkompatibilitätsgrad des Legacy-Systems:
Säule 3: Knowledge Representation (für unstrukturierte Daten)
Das wertvollste Unternehmenswissen steckt häufig nicht in Tabellen, sondern in Dokumenten, E-Mails und Nachrichten. Dieses Problem, oft als “The Unstructured Tsunami” bezeichnet, führt zu einer “Knowledge Crisis”, deren Ursprung in drei Jahrzehnten liegt, in denen sich Unternehmen zu 90% auf strukturierte Daten konzentriert haben. Traditionelle Ansätze wie einfaches Chunk-and-Embed in RAG-Systemen versagen häufig, führen zu Halluzinationen und Vertrauensverlust. Der Grund dafür ist, dass KI im Gegensatz zu Menschen ohne semantische Anreicherung keinen Kontext verstehen kann.
Die Lösung ist Knowledge Representation – eine neue, unverzichtbare Wissensschicht über der Datenschicht. Zum ersten Mal in der Geschichte brauchen wir eine Wissensschicht über der Datenschicht, damit KI wirklich erfolgreich sein kann.
Schlüsselkomponenten dieser Lösung sind:
- Semantische Anreicherung (Semantic Enrichment): Rohtexte werden mit Kontext und Bedeutung angereichert. Statt nur den Patenttext zu speichern, wird beispielsweise ergänzt “Dieses Patent verwendet genetische Modifikationsmethode X aus der USA-Region.”
- Knowledge Graphs: Diese Graphen strukturieren Beziehungen zwischen Entitäten (z.B. Methode X → verwandte Patente → regionale Variationen), was der KI ermöglicht, präzise, kontextuelle Abfragen durchzuführen.
- Hybride Retrieval-Strategien: Die Kombination aus Metadaten-basierter Filterung, Vektorsuche und Reasoning Layer überwindet traditionelle RAG-Limitationen und liefert genaue, zuverlässige und auditierbare Antworten.
Diese drei Säulen sind keine isolierten Konzepte. Ihre wahre Stärke entfaltet sich erst, wenn sie sich zu einer einheitlichen, integrierten architektonischen Lösung verbinden.
Lösung und Vision: Knowledge Lake Architektur
Die wahre Kraft für Generative KI entsteht nicht aus einzelnen Säulen isoliert, sondern aus ihrer intelligenten Integration. Die Knowledge Lake Vision stellt den nächsten evolutionären Schritt in der Unternehmensdatenarchitektur dar, indem sie alle drei Säulen in ein kohärentes Ganzes integriert.
Gemeinsame Schicht: Semantische Anreicherung als Schlüssel zum Erfolg
Die Schnittstelle zwischen dem AI Ready Data Paradigma und Knowledge Representation ist die Semantic Enrichment Layer. Das ist der Ort, “an dem saubere, verwaltete Daten auf Bedeutung treffen”. Genau diese Schicht ist der wahre Enabler für Generative KI. Indem sie verifizierte Daten mit Kontext verbindet, ermöglicht sie KI-Assistenten, vertrauenswürdig, erklärbar und compliant zu werden.
Knowledge Lake Architektur-Komponenten
Der Knowledge Lake ersetzt nicht bestehende Data Lakes, sondern stellt ihre Evolution dar. Ein fundamentaler Wandel findet statt: von der Bereitstellung roher Daten für Analysetools zur Bereitstellung strukturierten Wissens für KI-Systeme.
Die Knowledge Lake Architektur besteht aus folgenden Hauptkomponenten:
- Phasierte strukturierte und unstrukturierte Daten aus bestehenden Data Lakes
- MCP-Zugriffsschichten (dünn/dick) für sichere Integration mit Legacy-Systemen
- Knowledge Graphs mit semantischer Anreicherung als zentrales Element für Kontext- und Beziehungsspeicherung
- Metadaten-Annotationen, die alle Schichten verbinden und Konsistenz gewährleisten
- Spezialisierte Speicher für Governance- und evaluationsrelevante Daten (Testsets, versionierte Prompts, verifizierte Antworten)
- Persistente Speicher für AI-Agent-Memory und Audit-Trails ihrer Entscheidungsfindung
Praxisbeweise: Case Studies
Die folgenden Beispiele sind keine theoretischen Konzepte. Es handelt sich um reale Lösungen, die spezifische Unternehmensprobleme durch Implementierung von AI-Ready Datenprinzipien gelöst und den Weg gezeigt haben, aus der “Pilot-Hölle” zu entkommen.
Case Study: Globale Bank (strukturierte Daten-Herausforderung)
- Problem: Eine globale Bank stand vor der Herausforderung, dass Legacy-Systeme (COBOL, Mainframes) und unflexible Data Warehouses dazu führten, dass die Integration jedes neuen AI-Use-Cases mehrere Monate in Anspruch nahm. Dieser enorme Overhead und die resultierende Langsamkeit blockierten jede Innovation.
- Lösung: Es wurde eine dedizierte Datenplattform implementiert, die KI-Initiativen effektiv von Core-Systemen entkoppelte. Spezialisierte APIs (praktische MCP-Implementierung) stellten KI-Modellen ausschließlich saubere, relevante und auditierbare Daten bereit. Teil der Lösung war die Einführung eines robusten Governance-Frameworks mit Testsets zur Gewährleistung regulatorischer Compliance.
- Ergebnis: Die KI-Projektauslieferung beschleunigte sich dramatisch: von mehreren Monaten auf wenige Wochen. Das ermöglichte das Deployment mehrerer zentraler KI-Lösungen (z.B. Risk Scoring, Transaktionszusammenfassung) in den produktiven Betrieb, was zuvor nicht möglich war.
Case Study: Investmentgesellschaft (unstrukturierte Daten-Herausforderung)
- Problem: Analysten einer Investmentgesellschaft hatten Schwierigkeiten bei der Verarbeitung massiver und komplexer Finanzberichte. Traditionelle RAG-Methoden (chunk-and-embed) versagten komplett, generierten unzuverlässige Antworten und führten zu tiefer Frustration und Vertrauensverlust in die KI.
- Lösung: Es wurde ein hybrider Suchansatz eingeführt, der Vektorsuche mit Full-Document-Reasoning kombiniert. Die Knowledge Representation Layer spielte eine Schlüsselrolle und versorgte Daten mit notwendigem semantischem Kontext und Präzision. Zusätzlich wurde das MCP-Protokoll genutzt, um Schwächen in Drittanbieter-APIs zu kompensieren, über die zusätzliche Daten bezogen wurden.
- Ergebnis: Die Situation wandelte sich von Frustration zu Vertrauen. KI-generierte Antworten wurden zuverlässig, vollständig und auditierbar. Dadurch stieg die Arbeitseffizienz der Analysten erheblich und die Qualität ihrer Outputs verbesserte sich deutlich.
Geschäftsnutzen und Ergebnisse
Der Übergang zu AI-Ready Datenarchitektur ist nicht nur eine technische Maßnahme. Er ist ein strategischer Schritt, der konkreten, messbaren und nachhaltigen Geschäftswert in der gesamten Organisation schafft.
Fünf zentrale Geschäftsergebnisse
- Return on Investment in bestehende Infrastruktur (ROI): Dieser Ansatz ermöglicht es erstmals, millionenschwere Investitionen in Data Warehouses und Lakes jenseits des traditionellen Reportings zu monetarisieren. Bestehende Datenquellen werden zur Grundlage für hochwertige KI-Anwendungen.
- Speed to Market: Das Deployment neuer AI-Use-Cases beschleunigt sich von Monaten auf Wochen. Unternehmen können schneller auf Marktchancen reagieren und vor der Konkurrenz innovieren.
- Risikominderung: Durch die Implementierung solider Governance, robuster Test- und Evaluationsframeworks wird Zuverlässigkeit, Sicherheit und Vorhersagbarkeit von KI-Systemen gewährleistet, was für ihr Deployment in kritischen Geschäftsprozessen entscheidend ist.
- Wettbewerbsvorteil: Das Erschließen von Wert aus bisher ungenutzten unstrukturierten Daten eröffnet Zugang zu Wissen, das Wettbewerber nicht besitzen. Diese Informationsasymmetrie wird zur Quelle eines nachhaltigen Wettbewerbsvorteils.
- Regulatorische Compliance: Eine Architektur mit eingebauter Erklärbarkeit und Data Lineage gewährleistet vollständige Auditierbarkeit und Compliance mit strengen Vorschriften wie dem EU AI Act.
Strategischer Denkwandel
Dieser Ansatz erfordert einen strategischen Wandel in der Art, wie wir über Daten und KI denken.
Zentrale Prinzipien sind:
- Nicht ersetzen, sondern das bestehende Datenökosystem erweitern und weiterentwickeln
- Nicht umbauen, sondern AI-Ready Schichten über bestehenden Systemen schaffen
- Nicht warten, sondern diese Fähigkeiten inkrementell aufbauen und sich zunächst auf Quick Wins konzentrieren
Auf diese Weise verwandelt sich Ihre bestehende Dateninfrastruktur endlich in die AI-Engine , die sie immer sein sollte.
Aufruf zum Handeln: Ihr Erste-Quartal-Plan
Erfolg mit KI entsteht nicht durch Modelle selbst, sondern den systematischen Aufbau solider Datenfundamente. Die folgenden Schritte stellen einen praktischen und umsetzbaren Plan, um aus der “Pilot-Hölle” auszubrechen und skalierbare KI-Lösungen aufzubauen.
Woche 1: Führen Sie ein kompromissloses Audit durch
Auditieren Sie Ihre bestehende Datenarchitektur entlang der drei Säulen (AI-Ready Data, MCP, Knowledge Representation) und identifizieren Sie die größten Schwachstellen. Das Audit sollte folgende Fragen beantworten:
- Welche AI-Use-Cases stecken aufgrund von Engpässen in der Datenvorbereitung fest?
- Welche kritischen Daten sind in Legacy-Systemen gefangen und blockieren Innovation?
- Wo geht Vertrauen in KI verloren, weil ihnen der richtige Kontext aus unstrukturierten Daten fehlt?
Monat 1: Identifizierung wertvollster Quick Winsx
Basierend auf dem Audit identifizieren Sie jene Chancen, die schnell sichtbaren und messbaren Impact bringen. Konzentrieren Sie sich auf folgende Fragen:
- Welche Legacy-System-Integration über MCP könnte die meisten AI-Use-Cases freischalten?
- Welche unstrukturierte Datenquelle enthält das wertvollste Geschäftswissen, das durch Knowledge Representation zugänglich gemacht werden kann?
- Welcher bestehende KI-Pilot könnte in Produktion gehen, wenn er die richtigen Datenfundamente hätte?
Quartal 1: Aufbau Ihrer ersten AI-Ready Fähigkeit
Transformieren Sie die identifizierte Chancen in konkrete Ergebnisse. Setzen Sie sich das Ziel, die erste funktionale Komponente Ihrer neuen Architektur aufzubauen:
- Implementieren Sie einen MCP-Server für das kritischste Legacy-System
- Erstellen Sie eine Knowledge Representation Layer für die wertvollsten unstrukturierten Daten
- Führen Sie erste Evaluationsdatensätze ein, um KI-Qualität und -Zuverlässigkeit kontinuierlich zu messen
Fazit: Die Zukunft gehört KI-nativen Datenumgebungen
Die Hauptidee ist klar: Hören Sie auf, traditionelle Datenarchitektur dazu zu zwingen, KI-Systeme zu unterstützen. Beginnen Sie stattdessen mit dem Aufbau von Datenumgebungen, die von Grund auf nativ für KI konzipert sind, die persistente KI-Bereitschaftszustände aufrechterhalten und gleichzeitig Unternehmensinitiativen skalieren.
Unternehmen, die diesen Wandel frühzeitig verstehen und umsetzen, werden nicht nur bessere KI-Lösungen besitzen– sie werden Lösungen besitzen, die im Unternehmensmaßstab tatsächlich funktionieren und echten Wert liefert.
Die Frage ist: Werden Sie dazugehören?
