E.ON: Retenční kampaň snížila počet podaných výpovědí o 50%
Díky modelům pokročilé analytiky, které v prostředí Databricks vyvinula Adastra.
snížení odchodu zákazníků
vyšší úspěšnost v identifikaci ohrožených zákazníků
vyšší efektivita cílení oproti náhodnému výběru

VÝZVA
Nejvhodnější klienti k oslovení
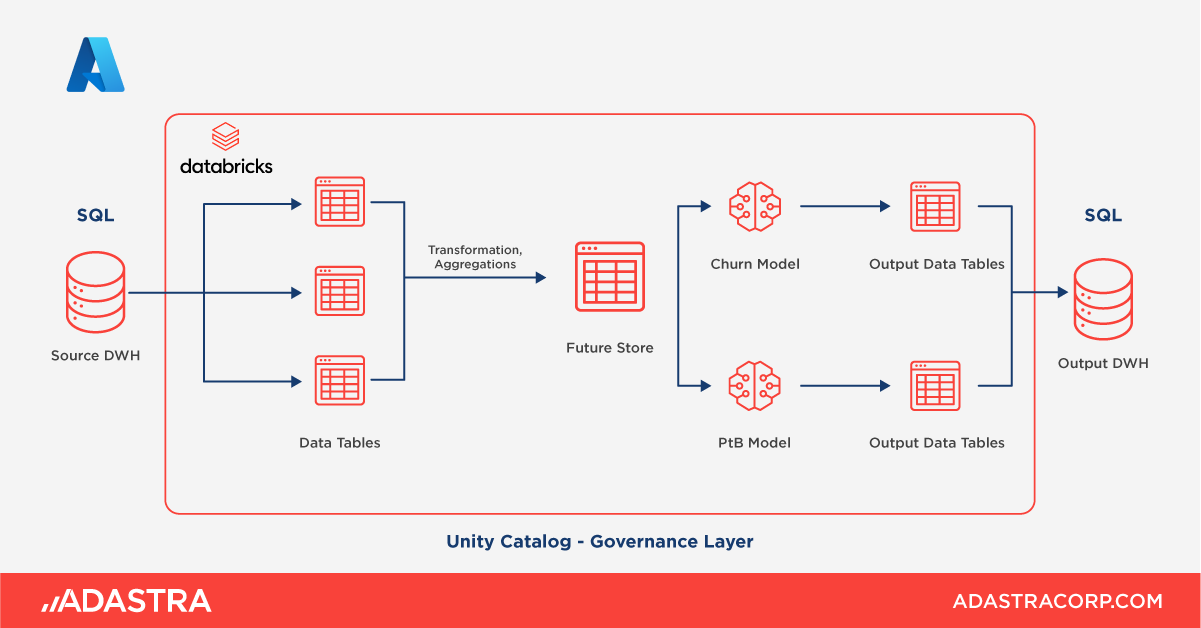
Pro včasné oslovení zákazníků jsme navrhli a zautomatizovali proces provozovaný na cloudu Microsoft Azure. Našimi úkoly bylo:
- Navrhnout analytický datamart, který bude obsahovat všechna data potřebná a zajímavá pro tvorbu predikčního ML (machine learning) modelu.
- Z datového skladu automaticky transformovat a loadovat data do tohoto datamartu.
- Data z datamartu použít na platformě Databricks. Tam také natrénovat, vyhodnotit, interpretovat a automatizovat ML model s cílem
-
- identifikovat zákazníky, kteří mají sklon odejít ke konkurenci
- určit faktory, které vedou k jejich nespokojenosti tak, aby mohl E.ON tyto zákazníky včas zacílit optimálním druhem retenční nabídky.
ŘEŠENÍ
Z cca 300 základních atributů v datamartu jsme připravili 7500+ pokročilých prediktorů
V rámci business analýzy jsme zmapovali problematiku odchodovosti, výpovědí, převodů smluv mezi distributory energie a legislativy, která tuto problematiku upravuje. Definovali jsme data potřebná nejen pro vývoj tohoto ML modelu, ale i pro další use-casy zamýšlené do budoucna. Společně s byznys partnery z E.ONu jsme v datovém skladu identifikovali klíčová data, navrhli jejich transformaci a koncept analytického datamartu. Následně jsme synchronizovali automatický přenos dat z datamartu do prostředí platformy Databricks.
Z cca 300 základních atributů jsme v Databricks vytvořili bohatou sadu prediktorů, která čítá přes 7500 odvozených ukazatelů. Nad tímto analytickým souborem jsme vyvíjeli ML model, jeho trénink probíhal nad datovým souborem o 10 milionech záznamů a 750 atributech.
Skóre modelu, tj. pravděpodobnost, že zákazník v nejbližší době podá výpověď, pravidelně exportujeme z Databricks do datového skladu, aby je mohl E.ON použít pro práci s klienty. Celý proces běží automaticky s měsíčním opakováním.
VÝSLEDKY
ML model odhalí dvakrát víc zákazníků ohrožených odchodem než původní expertní přístup
Při výběru nejohroženějších zákazníků do retenční kampaně pomocí ML modelu jsme dosáhli 2x vyšší úspěšnosti než za použití původního přístupu (manuální výběr pomocí expertních pravidel) a zároveň 21x vyšší úspěšnosti než bychom dosáhli v případě náhodného cílení.
Samotná proaktivní retenční kampaň, založená na výsledcích modelu, dokázala u 5 % nejohroženějších zákazníků snížit množství podaných výpovědí o 50 %.
- 50% snížení odchodu zákazníků u 5 % nejohroženějších zákazníků díky proaktivní retenční kampani založené na výsledcích modelu.
- 2x vyšší úspěšnost v identifikaci ohrožených zákazníků oproti původnímu expertnímu přístupu.
- 21x vyšší efektivita cílení oproti náhodnému výběru.



Máte zájem o podobné řešení?
